|
I am a Robotics PhD student at Carnegie Mellon University advised by Katerina Fragkiadaki and Jeff Schneider. Previously, I worked at Meta AI and completed my undergrad at UC Berkeley where I was fortunate to work with Dinesh Jayaraman, Roberto Calandra, Sergey Levine, and Kris Pister. My research focuses on developing learning-based control algorithms at the intersection of generative modeling, model-based planning, and reinforcement learning. In my PhD, I have primarily focused on applying these ideas to autonomous driving. During my undergrad, I worked on a variety of real-world robot learning problems ranging from low-cost manipulation to microrobot locomotion. |

|
|
|
|
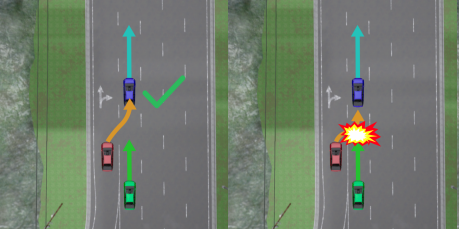
Adam Villaflor, Brian Yang, Katerina Fragkiadaki, John Dolan, Jeff Schneider In submission |
|
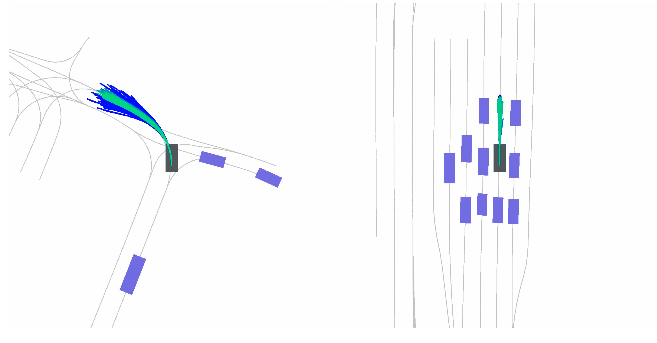
Brian Yang, Huangyuan Su, Nikolaos Gkanatsios, Tsung-Wei Ke, Ayush Jain, Jeff Schneider, Katerina Fragkiadaki CVPR 2024 arXiv / pdf / website |

|
Adam Villaflor, Brian Yang, Huangyuan Su, Katerina Fragkiadaki, John Dolan, Jeff Schneider ICRA 2024 arXiv / pdf / code |

|
Charles Sun, Jędrzej Orbik, Coline Devin, Brian Yang, Abhishek Gupta, Glen Berseth, Sergey Levine CoRL 2022 arXiv / pdf / blog / code |

|
Brian Yang*, Dinesh Jayaraman*, Glen Berseth, Alexei Efros, Sergey Levine RA-L + ICRA 2020 arXiv / pdf / project page |

|
Mike Lambeta*, Po-Wei Chou*, Stephen Tian, Brian Yang, Benjamin Maloon, Victoria Rose Most, Dave Stroud, Raymond Santos, Ahmad Byagowi, Gregg Kammerer, Dinesh Jayaraman, Roberto Calandra RA-L + ICRA 2020 arXiv / pdf / project page |

|
Brian Yang, Dinesh Jayaraman, Sergey Levine ICRA 2019 arXiv / pdf / project page / code |
|
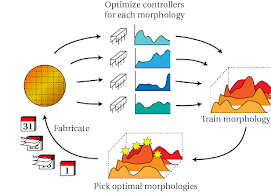
Thomas Liao, Grant Wang, Brian Yang, Rene Lee, Kris Pister, Sergey Levine, Roberto Calandra ICRA 2019 arxiv / pdf / project page / code |

|
Brian Yang*, Grant Wang*, Roberto Calandra, Daniel Contreras, Sergey Levine, Kris Pister RA-L + ICRA 2018 arXiv / pdf / project page / code |
|
Template taken from here. |